本文在 Spark 及图计算引擎 GraphX 的基础上,设计并实现一套用于顶点分析的社交网络分析系统,为使用 Spark 进行大规模社交网络的顶点分析提供具体 接口,包括社交网络的图模型构建、顶点重要度估值、顶点间路径的...
”Spark 计算引擎 GraphX 社交网络分析系统 毕业设计“ 的搜索结果
本文在Spark及图计算引擎GraphX的基础上,设计并实现一套用于顶点分析的社交网络分析系统,为使用Spark进行大规模社交网络的顶点分析提供具体接口,包括社交网络的图模型构建、顶点重要度估值、顶点间路径的计算、...
本文在Spark及图计算引擎GraphX的基础上,设计并实现一套用于顶点分析的社交网络分析系统,为使用Spark进行大规模社交网络的顶点分析提供具体接口,包括社交网络的图模型构建、顶点重要度估值、顶点间路径的计算、...
本文在Spark及图计算引擎GraphX的基础上,设计并实现一套用于顶点分析的社交网络分析系统,为使用Spark进行大规模社交网络的顶点分析提供具体接口,包括社交网络的图模型构建、顶点重要度估值、顶点间路径的计算、...

Spark GraphX实战
标签: Spark
第3部分 更多内容
它是一个开源的分布式流处理框架,具有高容错性、可靠性、低延迟等特征,能够支持实时计算场景下的超大数据量、高吞吐量的数据处理需求。技术选型标准:无论是开源还是商用版本,Apache Flink都已经成为多家大厂领跑...
本文在Spark及图计算引擎GraphX的基础上,设计并实现一套用于顶点分析的社交网络分析系统,为使用Spark进行大规模社交网络的顶点分析提供具体接口,包括社交网络的图模型构建、顶点重要度估值、顶点间路径的计算、...
OrientDB Java连接操作https://www.yiibai.com/orientdb/orientdb_java_interface.html 数据结构图总结https://blog.csdn.net/LJFYYJ/article/details/80293263 图数据库——大数据时代的高铁... ...
源于2014年,由CSDN主办的中国Spark技术峰会已成功举办两届,而到了2016年,峰会更得到了Spark护航者Databricks的支持,所有议题均由Databricks联合创始人兼首席架构师Reynold Xin及峰会主席陈超联合把关。...
查询引擎 一、Phoenix 贡献者::Salesforce 简介:这是一个Java中间层,可以让开发者在Apache HBase上执行SQL查询。Phoenix完全使用Java编写,代码位于GitHub上,并且提供了一个客户端可嵌入的JDBC驱动。 ...
11 月 2 号 - 11 月 3 号,...作为图数据库技术的代表,Nebula Graph 总监——吴敏在本次大会上将会讲述了大规模分布式图数据库设计思考和实践。在信息爆发式增长和内容平台遍地开花的信息时代,图数据库在当中扮演...
本文在Spark及图计算引擎GraphX的基础上,设计并实现一套用于顶点分析的社交网络分析系统,为使用Spark进行大规模社交网络的顶点分析提供具体接口,包括社交网络的图模型构建、顶点重要度估值、顶点间路径的计算、...
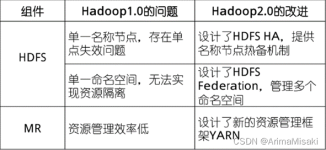
MapReduce是一个分布式运算程序的编程框架,是用户开发"Hadoop的数据分析应用"的核心框架。MapReduce的思想核心是"分而治之",适用于大量复杂的任务处理场景(大规模数据处理场景)。Map负责"分",即把复杂的任务...

机器学习与深度学习资料整理
标签: 机器学习
《Brief History of Machine Learning》介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机、神经网络、决策树、SVM、Adaboost到随机森林、Deep Learning.《Deep Learning in Neural Networks: An Overview...
主题是图神经网络在推荐广告场景中的一个应用,分享的内容分为三大块: 第一个是图神经网络的一个介绍; 然后第二块就是图神经网络在推荐广告中的一些应用、一些案例; 然后第三块是图神经网络在工业界落地的时候,...
查询引擎 一、Phoenix 贡献者::Salesforce 简介:这是一个Java中间层,可以让开发者在Apache HBase上执行SQL查询。Phoenix完全使用Java编写,代码位于GitHub上,并且提供了一个客户端可嵌入的JDBC驱动。 ...
动辄达到数百TB甚至数十至数百PB规模的行业/企业大数据已远远超出了现有传统的计算技术和信息系统的处理能力,因此,寻求有效的大数据处理技术、方法和手段已经成为现实世界的迫切需求。 由于大数据处理需求的迫切...
机器学习与深度学习资料...介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机、神经网络、决策树、SVM、Adaboost到随机森林、Deep Learning. 《Deep Learning in Neural Networks: An Overview》 介绍:这
http://www.csdn.net/article/2015-07-07/2825148开源(Open ...另一方面,开源也给大数据技术构建了一个异常复杂的生态系统。每一天,都有一大堆“新”框架、“新”类库或“新”工具,犹如雨后春笋般涌出,乱花渐
主要基于对现阶段一些常用的大数据开源框架技术的整理,只是一些简单的介绍,并不是详细技术梳理。可能会有疏漏,发现再整理。参考得太多,就不一一列出来了。这只是作为一个梳理,对以后选型或者扩展的做个参考。
基于 Kafka 的实时计算引擎如何选择?Spark or Flink ?:点击这里 Kafka 应用实践与生态集成:点击这里 Druid 深入分析Druid存储结构:点击这里 Kylin、Druid、ClickHouse核心技术对比:点击这里 ClickHouse ...
查询引擎、流式计算、迭代计算、离线计算、键值存储、表格存储、文件存储、资源管理、日志收集系统、消息系统、分布式服务、集群管理、基础设施、搜索引擎、数据挖掘=监控 原文出处: 36大数据:一共81个,...
机器学习&深度学习入门学习资料大全(一)
推荐文章
- react常见面试题_recate面试-程序员宅基地
- 交叉编译jpeglib遇到的问题-程序员宅基地
- 【办公类-22-06】周计划系列(1)“信息窗” (2024年调整版本)-程序员宅基地
- SEO优化_百度seo resetful-程序员宅基地
- 回归预测 | Matlab实现HPO-ELM猎食者算法优化极限学习机的数据回归预测_猎食者优化算法-程序员宅基地
- 苹果发通谍拒绝“热更新”,中国程序猿“最受伤”-程序员宅基地
- 在VSCode中运行Jupyter Notebook_vscode jupyter notebook-程序员宅基地
- 老赵书托(2):计算机程序的构造与解释-程序员宅基地
- 图像处理之常见二值化方法汇总-程序员宅基地
- 基于springboot实现社区团购系统项目【项目源码+论文说明】计算机毕业设计-程序员宅基地